voir aussi : à propos de l’interprétation
La musique de Taire : version neuromimétique
Frédéric Voisin, février-mai 2002.
extrait de : Revue&Corrigée n°52
Je souhaite retracer dans le présent article l’interprétation faite par un réseau de neurones artificiels (et le mien) de Taire, partition musicale écrite par Kasper T. Toeplitz pour ordinateur solo, sur une chorégraphie de Myriam Gourfink, créée au Centre National de la Danse de Paris le 21 février 2001. Il s’agit d’une recherche en cours, entreprise depuis plusieurs années, sur l’application des techniques de l’intelligence artificielle dans la création musicale, à travers les réseaux de neurones, ou dans la création chorégraphique, à travers le calcul symbolique (note 1). C’est au travers de projets menés avec Kasper Toeplitz, puis ensemble, avec Myriam Gourfink, que je trouvais le contexte pour cette recherche : un projet qui pouvait se planifier en termes d’années et d’amitié. Taire fut ainsi pour moi la première mise en œuvre d’un réseau de neurones exécutant, en temps réel, une partition préétablie. Cette première version neuromimétique est destinée à évoluer au cours des différentes reprises de ce solo.
Taire est une chorégraphie de Myriam Gourfink. Il s’agit d’un solo d’environ deux heures dont la partition, écrite en partie au moyen du programme LOL (note 2), est représentée en notation Laban. La partition est disposée au sol selon un parcours laissé libre à la danseuse. Chaque interprétation est un choix combinatoire effectué par la danseuse parmi des « moments » écrits dont elle devra intégrer les transitions.
La musique, pour ordinateur solo live, a été composée par Kasper T. Toeplitz. Il s’agit d’un banc de 80 oscillateurs sinusoïdaux traversant le spectre sonore à peu près dans le temps de la chorégraphie, selon un parcours défini pour chaque oscillateur par une attraction globalement ascendante, mais localement libre. Cette attraction est variable dans le temps et n’est pas nécessairement identique pour chaque oscillateur. La musique débute et se termine dans l’imperceptible (des infra-basses aux extrêmes aigus).
Lorsque j’exécutai mon premier réseau de neurones, c’était dans Max (Cycling74-IRCAM), sur processeur 68030. Il s’agissait de l’objet MLP de Michael Lee et Matt Writt, de UCLA.
Je l’expérimentais à l’IRCAM pour l’oublier au plus vite, voyant bien que l’apprentissage de son utilisation déborderait du cadre des productions IRCAM, dureraient-elles plusieurs mois. Ce n’etait pourtant, je l’imaginais bien, qu’un petit bout de code, de quelques dizaines de lignes, dont on voit mal, a priori, ce qu’il peut avoir de neuronal.
Décidé de me remettre un peu aux mathématiques, je cherchais à en savoir plus, à comprendre le « truc » qui se cachait derrière l’objet, assez sceptique sur le fait qu’un semblant d’intelligence puisse être fait à coup de lois statistiques et de cybernétique.
Cependant, la nature des questions que j’ai pu rencontrer lors de l’élaboration d’un réseau de neurones artificiel pour jouer la musique de Taire déborde du seul domaine informatique : « N’est-ce pas un abus de langage de parler de »l’apprentissage« d’une machine ? Quelle transmission de quels savoirs ? Peut-on parler de transmission orale de connaissances vers une machine ? ».
Ecriture, informatique et oralité
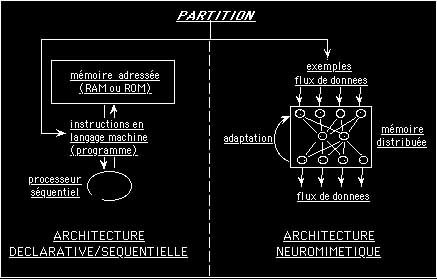
Le programme original de la partition musicale de Taire a été réalisé par le compositeur dans le programme Max. Il s’agit d’un environnement informatique traditionnel de type séquentiel : une programmation graphique, déclarative, constituée d’instructions explicites, décrites et ordonnées au moyen d’un ou plusieurs langages machine, puis exécutées séquentiellement par ladite machine (figure 1).
Le programme constitue donc, en quelque sorte, une partition logique s’adressant à un processeur. Cependant, à la différence de ce qu’on appelle traditionnellement une partition en musique, le programme n’est pas interprété(note 3), mais est lu et exécuté « mot à mot », sans que soit ouverte la possibilité, pour le processeur, de montrer des propriétés auto-émergentes issues de l’acquisition de connaissances, d’inférer des actions non pas seulement selon ce qui se passe (interaction), mais aussi selon ce qui a été appris.
figure 1 : Comparaison des deux programmes pour la musique de Taire : dans le cas d’un programme séquentiel, des instructions sont lues en mémoire et exécutées par un processeur au moins. Dans le cas d’un réseau de neurones, un flux de données est distribué et traité en parallèle par des cellules simple dont la mise en réseau constitue a la fois la mémoire et les propriétés dynamiques.
Les réseaux de neurones artificiels (RNA), dont le fonctionnement est plus ou moins inspiré des cellules et des structures nerveuses, sont capable d’apprentissage et d’inférence. Même s’il paraît encore difficile de réaliser un réseau artificiel atteignant un tant soit peu la complexité du cerveau humain, il n’en reste pas moins que certaines règles psychophysiologiques sont simulables numériquement. Il est déjà surprenant qu’une règle aussi simple que la loi de Hebb (note 4) permette des comportements de systèmes numériques comparables à ceux de systèmes nerveux simples.
Dans la mesure où il a été démontré, dans le règne animal, qu’à un apprentissage correspondent des changements synaptiques suscitant des changements comportementaux (note 5), que ces activités synaptiques peuvent être représentées et calculées numériquement, rien n’empêche d’apprendre à une machine par l’exemple, lorsque celle-ci simule des activités nerveuses. Or, instaurer les conditions d’un apprentissage par l’exemple constitue les conditions d’une transmission « orale », même si numérique, de connaissances. L’intérêt de ce type de « programmation » est qu’il permet la transmission de connaissances non nécessairement explicites ou formalisées : un réseau de neurones, lorsqu’il est bien constitué, artificiel ou non, infère des règles qui ne lui ont pas été apprises. Seulement, il reste difficile d’en retrouver une énonciation, une trace explicite, puisque ces inférences résident dans une matrice numérique décrivant les seules sensibilités synaptiques (cf. figures 2 et 3). J’ai donc developpe, en langage Lisp, un environnement neuromimetique permettant de controler un synthetiseur audio, tel que Max, par exemple.
Dans le cas de Taire, il s’agissait d’apprendre au réseau un parcours ascendant de plusieurs oscillateurs, avec, pour chacun, une certaine liberté, localement, de monter ou de descendre en fréquence. Seul le point de départ est fixé - 1 Hz environ - et la direction à atteindre – 20 kHz. L’idée était donc d’apprendre au RNA de Taire « l’idée » d’un parcours globalement ascendant mais pouvant localement descendre.
figure 2 : Représentation d’un RNA (sin0), avant apprentissage supervisé du contrôle d’un oscillateur audio.
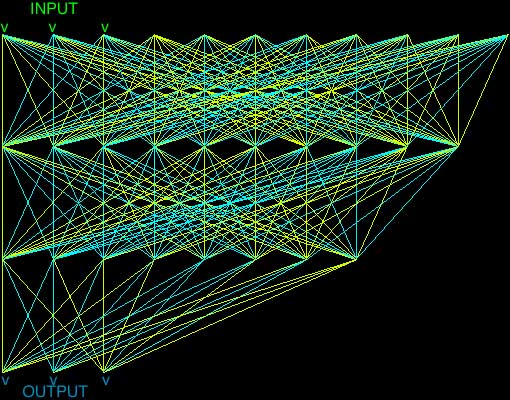
figure 3 : Le « même » RNA après apprentissage : les connections se sont structurées. Architecture, mémoire et apprentissage.

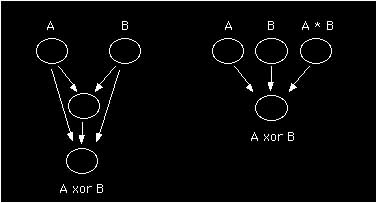
Les architectures possibles des RNA sont ouvertes et limitées à notre propre connaissance des moyens de leur apprentissage. Ce n’est que depuis la fin des années 80 – soit plus de trente ans après les premiers RNA – que nous savons créer les circonstances d’apprentissage pour des réseaux multicouches capables de résoudre des problèmes non triviaux (note 6). Cependant, si le nombre de couches traversées par le flux de données détermine la capacité d’un réseau de résoudre une tâche complexe, il n’est pas décisif. En effet, contrairement à la démonstration faite en 1969 par Minsky et Papert (note 7), un simple perceptron peut résoudre, par le simple ajout d’un neurone redondant sur l’une des couches existantes, un problème qu’il n’aurait pu résoudre sans ce neurone formellement inutile (cf. figure 4). Bien sûr, l’ajout d’un neurone, en particulier sur la couche d’entrée, nécessite un nouveau codage, une re-formulation des données. Ce type d’observation montre non seulement l’aspect critique de la représentation que l’on construit des faits (l’encodage), mais aussi la puissance de la plasticité des réseaux de neurones, qu’ils soient artificiels ou biologiques : l’apprentissage peut aussi agir sur l’architecture du réseau, par l’ajout ou la suppression de cellules ou de connexions.
figure 4 : Deux architectures neuromimétiques susceptibles d’apprendre la relation « A ou exclusif B » (relation XOR).
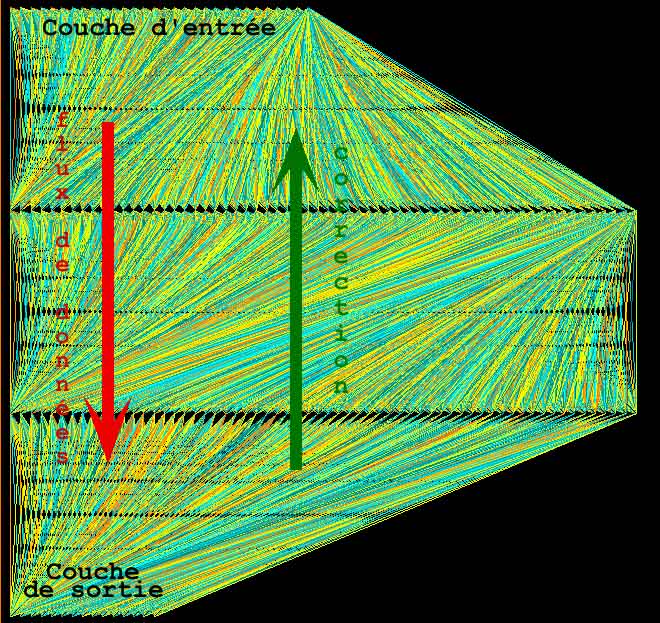
Le RNA utilisé pour Taire est un perceptron multicouches (figure 5). Il est composé de 169 neurones formels repartis sur quatre couches : une couche d’entrée, deux couches « cachées » et une couche chargée de fournir la réponse attendue pour chaque stimulus présenté à la couche d’entrée. Ce type d’architecture est, en principe, capable d’approcher des fonctions continues, telles que l’évolution en fréquence d’un oscillateur, et ce avec une erreur arbitraire (dépendante du temps que l’on se donne et du protocole d’apprentissage).
L’une des couches cachées est en rétroaction avec l’entrée, permettant d’intégrer l’état interne du réseau à un temps donné dans le calcul de son état au temps suivant ( note 8).
Il s’agît en quelque sorte de donner au réseau une mémoire de son état (qui nous échappe), cette mémoire influant sur son action en plus de ce qu’il « connaît ». (la rétroaction n’est pas dessinée dans les figures 2, 3 et 5 mais apparaît implicitement sur la couche d’entrée).
Le choix du nombre de neurones est en partie déterminé par la théorie, l’architecture du réseau et par l’encodage des données. Le rapport entre le nombre de neurones et le nombre d’exemples « différents » à apprendre ne peut dépasser un certain seuil au-delà duquel le réseau oublie (ou ne peut apprendre) les exemples qui lui sont présentés.
Cependant, si un grand nombre de neurones permet au réseau de bien mémoriser, celui-ci aura tendance à apprendre « par cœur » avec les inconvénients propres à ce type d’apprentissage : mauvaise aptitude à la généralisation, difficulté d’inférer une solution « acceptable » a un stimulus qui n’aura pas été appris…
L’apprentissage est dit supervisé dans la mesure où, pour chaque exemple donné au réseau, il lui est aussi donné la réponse attendue, lui permettant d’ajuster ces connexions synaptiques par une rétro-propagation de l’erreur sur l’ensemble des connexions pour chaque exemple. L’apprentissage est extrèmement couteux en terme de puissance de calcul. Ainsi, sur un processeur Apple G3, une fois l’architecture définie (quelques mois d’expérimentation, a heures perdues), l’apprentissage de Taire nécessite une trentaine d’heure de calcul (note 9)
Apprendre quoi, comment ?
Le parcours ascendant était « montré » au réseau au travers d’échantillons de fonctions de type exponentiel et logarithmique, à exposants divers. Chaque exemple est présenté plusieurs centaines de fois avec un bruit plus ou moins fort (note 10). Au départ, le réseau est « échauffé puis »refroidi« – pas trop, afin qu’il ne se crispe pas – au cours de l’apprentissage. Lorsque l’erreur mesurée à la sortie est jugée acceptable, alors il est prêt à jouer (c’est-à-dire que dès lors qu’il »entend« un vecteur proche de ce qu’il a appris, il joue ce qu’il »sait").
figure 5 : Réseau de neurones artificiels élaboré pour jouer la musique de Taire (les connections récurrentes de la couche interne vers l’entrée ne sont pas représentées). Les couleurs des liaisons représentent l’intensité des liaisons synaptiques : en couleurs froides des connexions inhibitrices, en couleurs chaudes les connexions excitatrices.
Execution
La notion de température du réseau que j’ai introduite précédemment appelle quelques explications : Elle fait référence, d’une part, à la notion du « simulé-recuit », méthode qui, en forçant le réseau à se tromper (en effectuant de fausses corrections), lui permet de ne pas tomber dans des « pièges ». La température peut aussi être une application de certaines lois thermonydamiques à l’ensemble de ses synapses : une élévation de la température l’amène à se tromper (de par l’agitation entrainée par la température) et donc à l’amener dans des états inconnus. Inversement, une basse température l’amène à se « figer », ne répéter que ce qu’il sait. Et par conséquent, à ne pas inférer.
Ce réseau a inspiré celui de L’Ecarlate, création de Myriam Gourfink, Kasper Toeplitz et moi-même, créée à l’IRCAM le 6 juin 2001. L’expérience acquise en termes d’apprentissage de réseau permet de reconsidérer les méthodes d’apprentissage que j’ai utilisées précédemment pour Taire. Il est possible en effet de se représenter la partition autrement. De même, comparer différents réseaux apprenant la même partition selon des méthodes – ou façons de voir – différentes. Ou encore jouer sur l’oubli, l’inhibition…
Notes
note 1
cf. Frederic Voisin : « LOL : Un environnement experimental de composition choregraphique »
in : Ec/cart, vol. 2, Eric Sadin éd., 2000.
version html
Cf. Frederic Voisin : « Ecriture choregraphique et informatique », revue Mouvement, mars 2001.
version html
note 2
LOL est un environnement informatique de composition choregraphique développé par moi-meme en collaboration avec Myriam Gourfink, Kasper T. Toeplitz et Laurence Marthouret.
lien vers LOL
note 3
Au sens general, non au sens informatique (interprete / compile)
note 4
Donald Hebb : The organization of Behavior, Wiley, New-York, 1949.
note 5
Cf. par exemple Eric Kandel & all : Principles of Neural Science, Elsevier, New-York, 1991.
note 6 retour
Il s’agît de la technique de la rétro-propagation de l’erreur permettant à des réseaux multicouches de résoudre des problèmes non linéairement séparables, tel que celui du « ou exclusif », rencontré en logique classique mais aussi dans certaines langues naturelles.
L’architecture en couches est inspirée de celle de régions du cortex où l’on a pu dénombrer jusqu’à sept couches d’interconnexions de neurones.
note 7
Minsky and Papert, 1969/1988 : Perceptions. in : Neurocomputing : pp. 157-169. Cambridge. MIT Press.
Il s’agit d’une démonstration formelle ayant abouti à la mise en veille, jusqu’à la fin des années 80, des recherches sur les réseaux de neurones.
note 8
Cf. J.L. Elman, 1990 : Finding structure in time. Cognitive Science 14 : pp. 179-211.
note 9
L’échec d’un apprentissage se traduit généralement par l’impossibilité du réseau d’atteindre une erreur inférieure au seuil fixé. Dans notre cas, nous cherchions à obtenir une précision de l’ordre du centième de ton sur l’ensemble du domaine auditif.
note 10
Ce qui est finalement tres rapide, 30 heures, malgre la lenteur du processeur (apple G4) - et c’est une chance - si on considere que Taire dure deux heures environ. 100 fois deux heures n’en font pas trente, meme avec les 35 heures !